Leo McCormack,
Archontis Politis,
Ville Pulkki
Parametric spatial audio effects based on the multi-directional decomposition of Ambisonic sound scenes
Companion page for the 23rd International Conference on Digital Audio Effects, Vienna, Austria, 2021.
Abstract
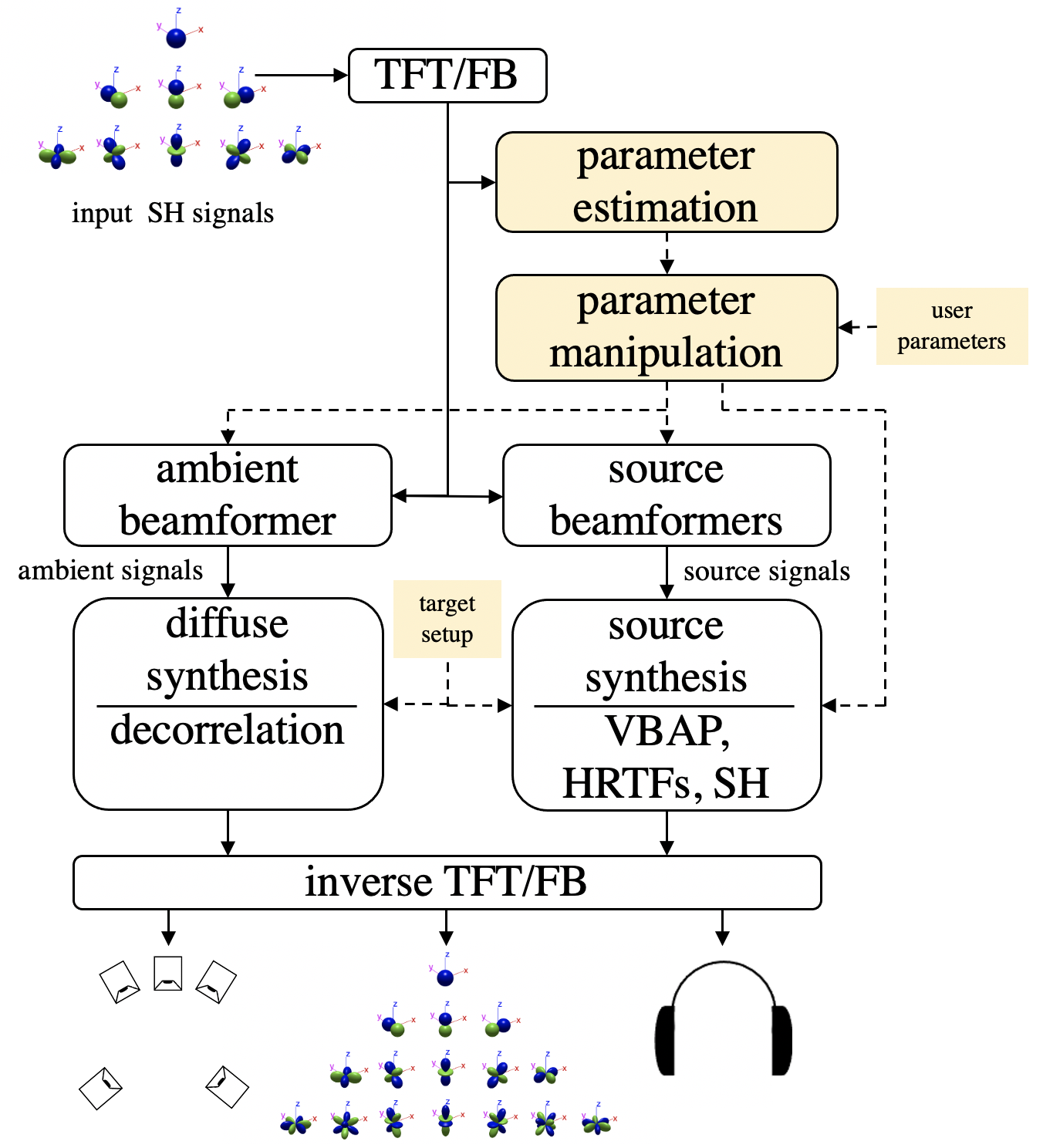
Decomposing a sound-field into its individual components and respective parameters can represent a convenient first-step towards offering the user an intuitive means of controlling spatial audio effects and sound-field modification tools. The majority of such tools available today, however, are instead limited to linear combinations of signals or employ a basic single-source parametric model. Therefore, the purpose of this paper is to present a parametric framework, which seeks to overcome these limitations by first dividing the sound-field into its multi-source and ambient components based on estimated spatial parameters. It is then demonstrated that by manipulating the spatial parameters prior to reproducing the scene, a number of sound-field modification and spatial audio effects may be realised; including: directional warping, listener translation, sound source tracking, spatial editing workflows and spatial side-chaining. Many of the effects described have also been implemented as real-time audio plug-ins, in order to demonstrate how a user may interact with such tools in practice.
Overview
It is demonstrated that through manipulations of spatial parameters, as analysed by the Coding and Multi-Parameterisation of Ambisonic Sound Scenes (COMPASS) method [1], several spatial effects and sould-field editing workflows can be realised.
VST downloads
To demonstrate how the described spatial effects and sould-field editing workflows can be implemented and interacted with in practice, five VST plug-ins have been developed and released with the plug-in suite found here.References
[1] Politis, A., Tervo S., and Pulkki, V. (2018) COMPASS: Coding and Multidirectional Parameterization of Ambisonic Sound Scenes.
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
Updated on Sunday 25th of April, 2021
This page uses HTML5, CSS, and JavaScript