This paper introduces a novel data-driven strategy for synthesizing gramophone noise textures. A diffusion probabilistic model is applied to generate highly realistic quasiperiodic noises. The proposed model is designed to generate samples of length equal to one disk revolution, but a method to generate plausible periodic variations between revolutions is also proposed. A guided approach is also applied as a conditioning method, where an audio signal generated with manually-tuned signal processing, is refined via reverse diffusion to appear more realistically sounding. The method is evaluated in a subjective listening test, where the participants were often unable to recognize the synthesized signals from the real ones. The synthetic noises produced with the best proposed unconditional method are statistically indistinguishable from real noise recordings. This work shows the potential of diffusion models for highly realistic audio synthesis tasks.
Real Gramophone Examples
Only-noise segments extracted from real gramophone recordings
Unconditional synthesis examples
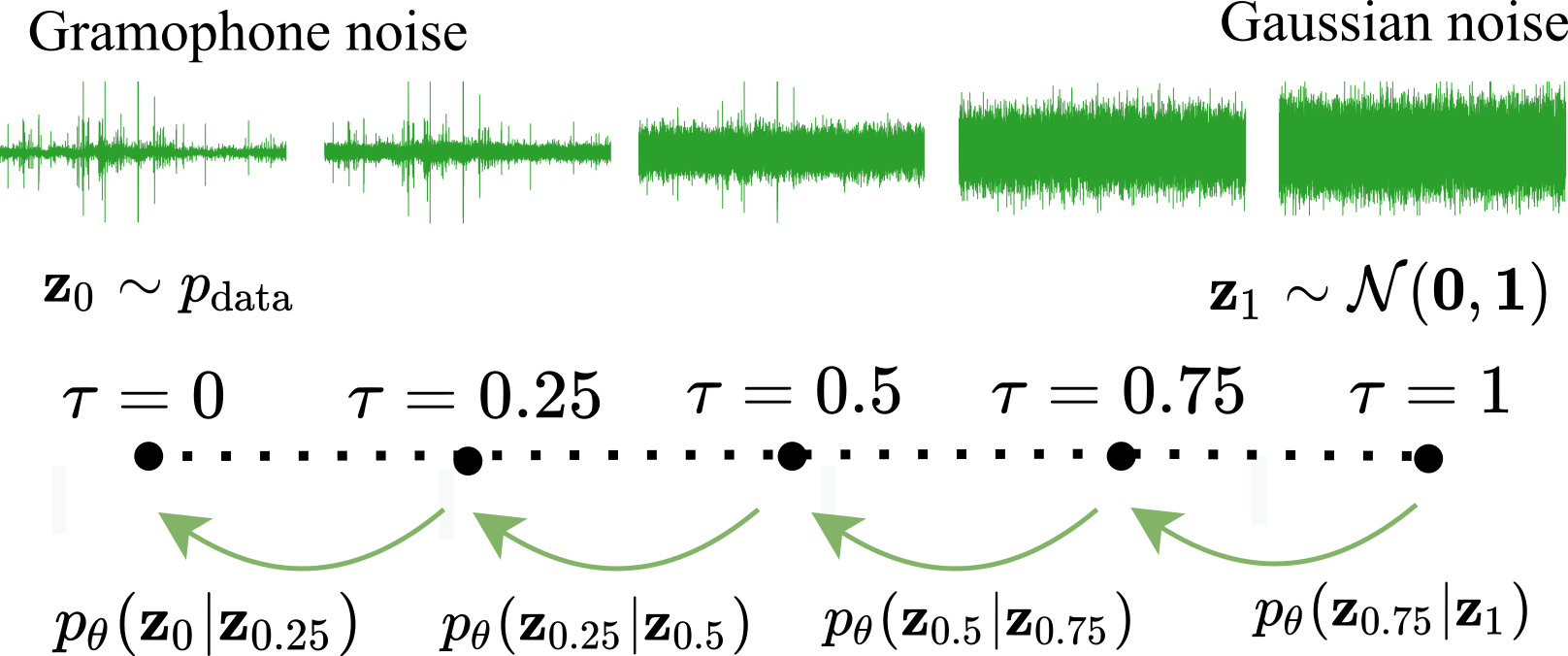
Fig. Diagram of the unconditional synthesis using a reverse difusion process
T=25
T=50
T=150
Guided synthesis examples
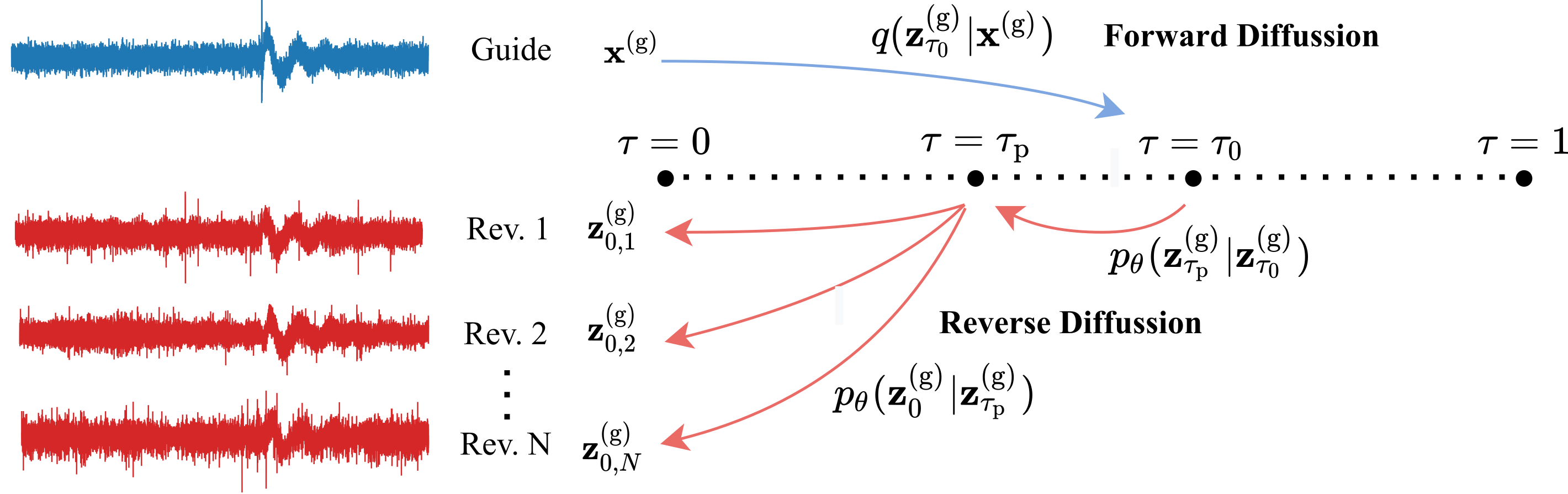
Fig. Diagram of the guided synthesis
Guides
𝜏0=0.33
𝜏0=0.5
𝜏0=0.66
Extra: Other audio texture synthesis
In order to explore the potential of the presented diffusion model for audio texture synthesis, we experimented with retraining the model with other kinds of (noisy) audio textures. We used audio examples from different classes of the AudioSet dataset. Below, we uploaded some audio examples of the class, and some unconditionally generated examples. Note that, for convenience, the model was trained with a fixed reduced sequence length of 1 second.