A two-stage U-Net for high-fidelity denoising of historical recordings
Eloi Moliner and Vesa Välimäki
Companion page for a paper submitted to IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2022
Singapore, May, 2022
The article can be downloaded here.


Abstract
Enhancing the sound quality of historical music recordings is a long-standing problem. This paper presents a novel denoising method based on a fully-convolutional deep neural network. A two-stage U-Net model architecture is designed to model and suppress the degradations with high fidelity. The method processes the time-frequency representation of audio, and is trained using realistic noisy data to jointly remove hiss, clicks, thumps, and other common additive disturbances from old analog discs. The proposed model outperforms previous methods in both objective and subjective metrics. The results of a formal blind listening test show that the method can denoise real gramophone recordings with an excellent quality. This study shows the importance of realistic training data and the power of deep learning in audio restoration.
Listening test examples
We conducted a MUSHRA-based listening test comparing our proposed method with previous ones. The audio examples included in the test and the MUSHRA scores are publicly available.
Audio restoration examples
| Title | ID | Performer | Composer | Year |
|---|---|---|---|---|
| Second Rhapsodie | Edison (82169) | Sergei Rachmaninoff | Franz Liszt | 1919 |

| Title | ID | Performer | Composer | Year |
|---|---|---|---|---|
| Livery Stable Blues | Edison (82169) | Original Dixieland 'Jass' Band | Original Dixieland 'Jass' Band | 1917 |

| Title | ID | Performer | Composer | Year |
|---|---|---|---|---|
| Boulanger-Marsch | Anker 01210 | Albert Müller | Louis César Desormes | 1909 |

| Title | ID | Performer | Composer | Year |
|---|---|---|---|---|
| O Sole Mio | His Master's Voice (D.A.103) | Enrico Caruso | Di Capua | 1913 |


| Title | ID | Performer | Composer | Year |
|---|---|---|---|---|
| Peer Gynt - IN THE HALL OF THE MOUNTAIN KING | Aretino (A 1160) | Orchestra (probably Leeds & Catlin house orchestra) | Edvard Grieg | 1907 |

| Title | ID | Performer | Composer | Year |
|---|---|---|---|---|
| Fifth Symphony (1st movement-Allegro con brio-Part 1) | Victor (18124-A / 18124-B) | Victor Concert Orchestra | Beethoven | 1916 |

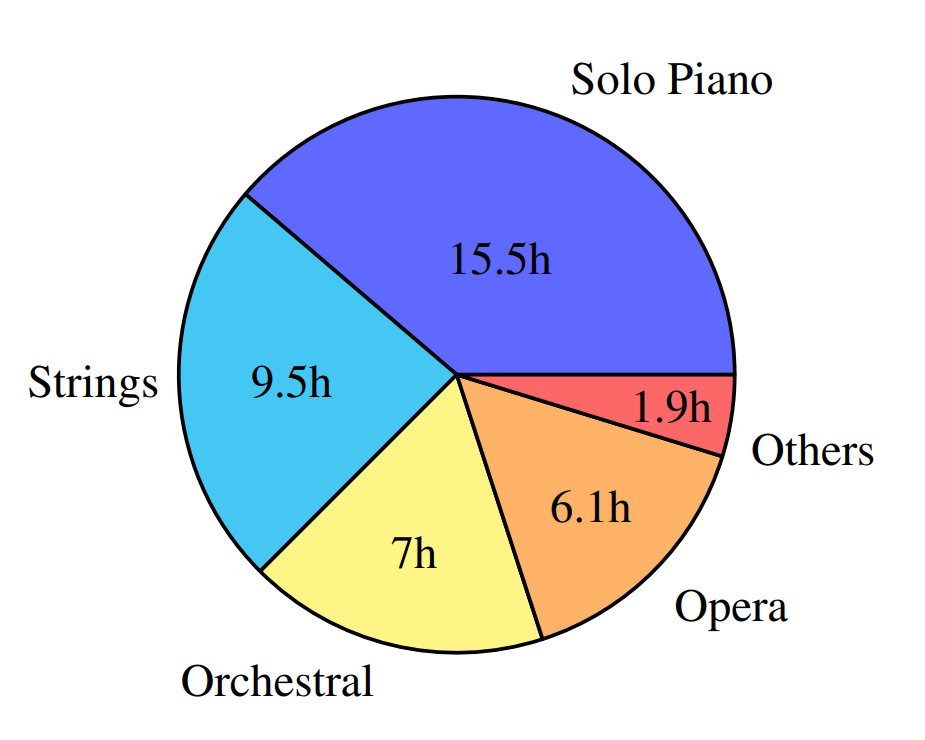
Clean Classical Music Dataset
We train our model using classical music. We use a refined and extended version of the MusicNet dataset. The older recordings with worse audio quality have been discarded, as they contained some background noises that could bias the training. In addition to the solo piano and string ensemble recordings from MusicNet, we added further orchestral and opera recordings from Internet Archive . The resulting dataset contains approximately 40 hours of classical music. The metadata file listing all the included music is available.
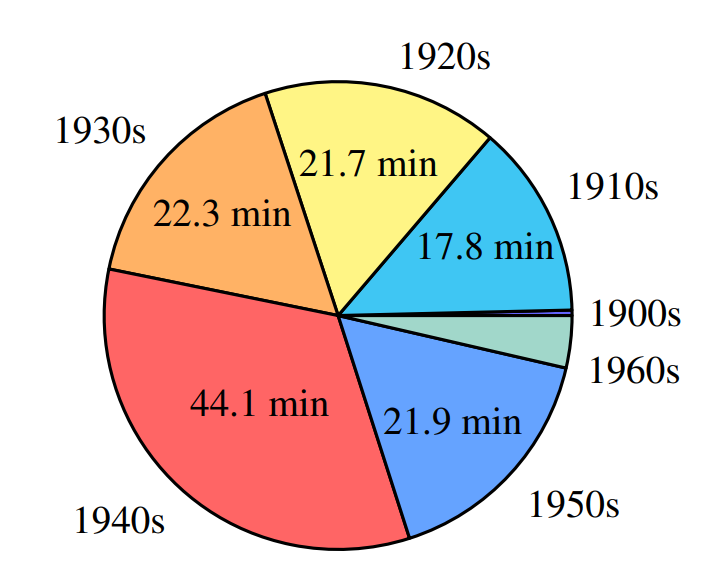
Gramophone Record Noise Dataset
We have collected a dataset of noise segments extracted from the The Great 78 Project, a large collection of digitized 78 RPM (rounds per minute) gramophone records. The noise excerpts we included in the dataset consist of a mixture of degradations coming from different sources: electrical circuit noise such as hiss, ambient noise from the recording environment, low-frequency rumble noise caused by the turntable, and noises caused by the irregularities in the storage medium in the form of clicks and thumps.
The dataset contains 139 min of noises, divided into 2430 segments from 1386 different recordings. The recordings used to generate the dataset are dated between the years 1902 and 1966.
Neural network-based noise selection
With the interest of implementing a robust noise segment extractor, we adopt a neural network-based approach. We define a light segment-based binary classifier, using 100-ms noisy segments with 50% overlap as inputs, each of them composed of 8x32 MFCC (Mel-frequency cepstral coefficient) sequences. The model architecture details are summarized in the following table:
| Layer | Num. filters / nodes | Kernel size | Stride | Activation |
|---|---|---|---|---|
| Convolution (x2) | 8-16 | 3x3 | 1x2 | ReLU |
| Convolution | 6 | 1x1 | - | ReLU |
| Fully connected (x2) | 6-16 | - | - | ReLU |
| Output | 1 | - | - | Sigmoid |
As training data, we use a smaller fraction of the dataset, which was manually collected by extracting only-noise segments from roughly 7 h of 78-RPM records. We then generate a binary encoded sequence to be used as training labels, establishing 1 for noise segments and 0 for the rest. Using the binary cross-entropy loss function, the neural network is trained to output a score between 0 and 1 defining the probability of a given segment to be an isolated noise candidate. We train the model for 200 epochs using the Adam optimizer with a learning rate of 5 x 10-7. At the inference stage, we select as noise slices all the audio passages longer than 2 s with all their segment scores higher than 0.15.
Source code
The code refering to the two-stage U-Net model and its training and inferencing is openly available at the github repository