Leo McCormack and
Symeon Delikaris-Manias,
Parametric first-order ambisonic decoding for headphones utilising the Cross-Pattern Coherence algorithm
Companion page for the 1st EAA Spatial Audio Signal Processing Symposium, Paris, France, 2019.
Abstract
Binaural ambisonics decoding is a means of reproducing a captured or synthesised sound-field, as described by a spherical harmonic representation, over headphones. The majority of ambisonic decoders proposed to date are based on a signal-independent approach; operating via a linear mapping between the input spherical harmonic signals and the output binaural signals. While this approach is computationally efficient, an impractically high input order is often required to deliver a sufficiently accurate rendition of the original spatial cues to the listener. This is especially problematic, as the vast majority of commercially available Ambisonics microphones are first-order, which ultimately results in numerous perceptual deficiencies during reproduction. Therefore, in this paper, a signal-dependent and parametric binaural ambisonic decoder is proposed, which is specifically intended to reproduce first-order input with high perceptual accuracy. The proposed method assumes a sound-field model of one source and one non-isotropic ambient component per narrow-band. It then employs the Cross-Pattern Coherence (CroPaC) post-filter, in order to segregate these components with improved spatial selectivity. Listening test results indicate that the proposed method, when using first-order input, performs similarly to third-order Ambisonics reproduction.
Overview of the method
The proposed first-order decoder employs a sound-field model comprising one source component and one non-isotropic ambient component per time-frequency tile. The method first estimates the source DoA via steered-response power (SRP) beamforming and subsequent peak-finding. The source stream is then segregated by steering a beamformer toward the estimated DoA, and employing an additional CroPaC [1] post-filtering operation to improve its spatial selectivity. The ambient stream is then simply the residual, once the source component has been subtracted from the input sound-field. The two streams are then binauralised and fed into an optimal mixing unit [2], along with the ambisonic prototype covariance matrix, in order to generate the binaural output. A block diagram of the proposed method is depicted below:
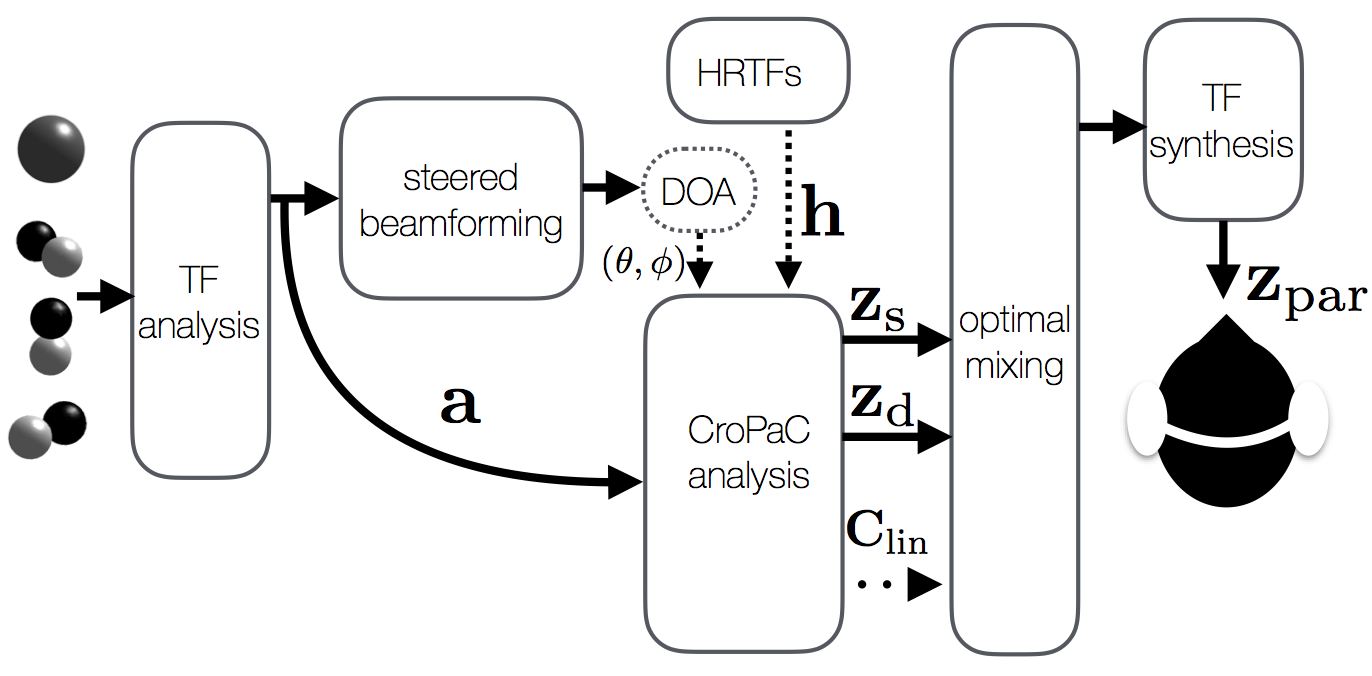
The proposed approach is inspired by the COMPASS method [3]. However, along with the CroPaC post-filter, it also employs instantaneous source direction estimation and synthesises the output in a linear manner as much as possible; in order to improve the fidelity of the output signals.
VST Audio Plug-in Download
The VST implementation of the proposed algorithm is bundled with the SPARTA suite, which can be downloaded from here.
This implementation employs the magnitude least-squares (magLS) ambisonic decoder [4] as the prototype, contrary to the spatial-resampling decoder employed for the listening tests described in the paper. The plug-in allows the user to import their own HRTFs via SOFA files, and also supports head-tracking via OSC messages. The user may also influence the direct/diffuse balance per frequency band; note that the streams are balanced when set in the middle (default).
Listening test results at a glance
Formal listening tests indicate that the proposed first-order decoder (CroPaC1) performs similarly to (or exceeds) third-order spatial re-sampling ambisonics decoding (Ambi3), in terms of the perceived spatial and timbral attributes of the reproduction; as shown in the plots below:
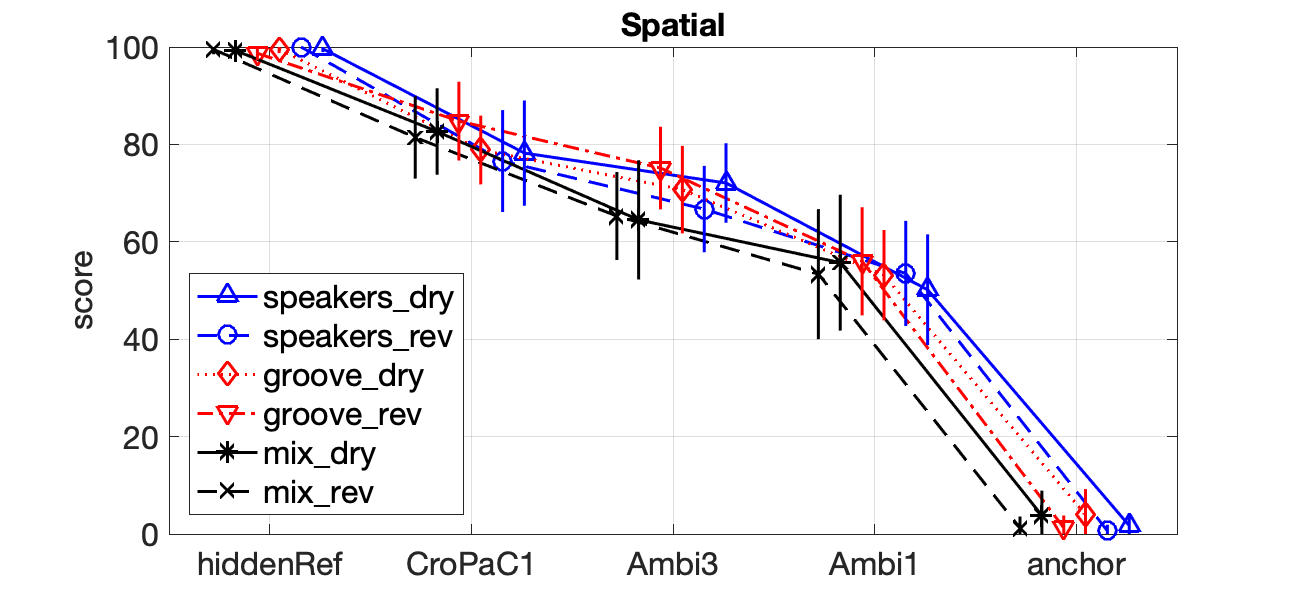
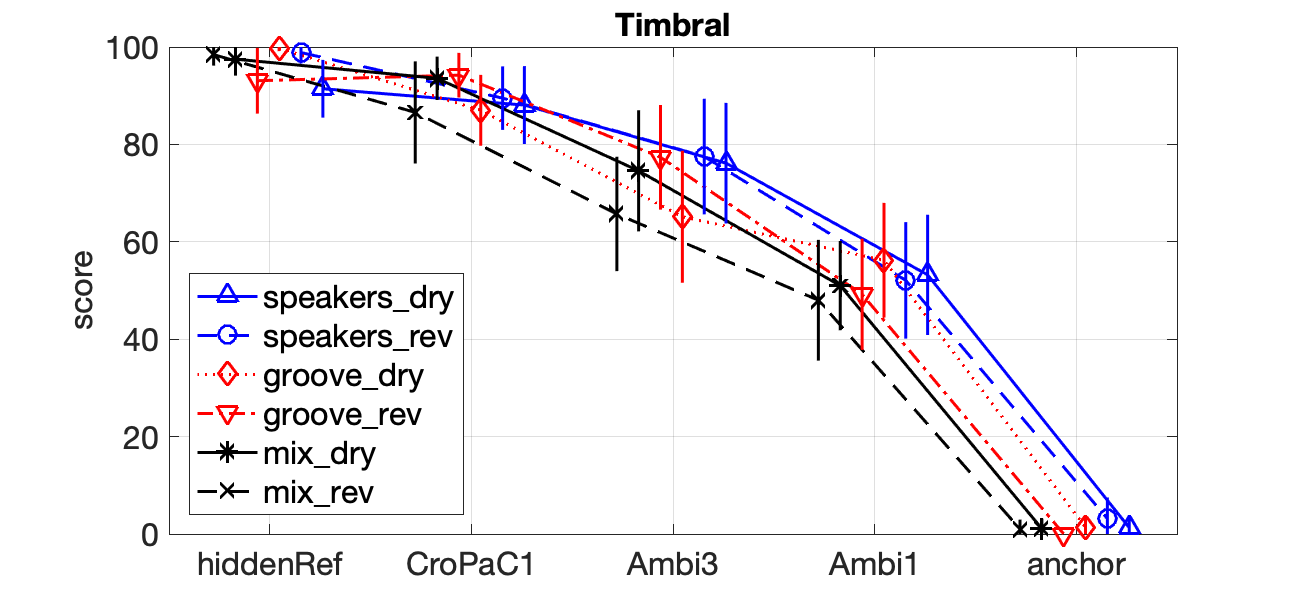
It should be highlighted that third- order ambisonics employs four times the number of input channels than that of the proposed method. This, therefore, represents a significant reduction in bandwidth, without compromising the perceived spatial accuracy or fidelity.
How to cite our work
McCormack, L., and Delkaris-Manias, S., "Parametric first-order ambisonic decoding for headphones utilising the Cross-Pattern Coherence algorithm", Proceedings 1st EAA Spatial Audio Signal Processing Symposium, Paris, France, Sep 6--7, 2018.
References
[1] Delikaris-Manias, S. and Pulkki, V. (2013). Cross Pattern Coherence Algorithm for Spatial Filtering Applications Utilizing Microphone Arrays.
Audio, Speech, and Language Processing, IEEE Transactions on , vol.21, no.11, pp.2356-2367.
[2] Vilkamo, J., Bäckström, T., and Kuntz, A. (2013). Optimized covariance domain framework for time–frequency processing of spatial audio.
Journal of the Audio Engineering Society, 61(6), 403-411.
[3] Politis, A., Tervo S., and Pulkki, V. (2018) COMPASS: Coding and Multidirectional Parameterization of Ambisonic Sound Scenes.
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
[4] Schörkhuber, C., Zaunschirm, M., and Höldrich, R. (2018). Binaural Rendering of Ambisonic Signals via Magnitude Least Squares.
In Proceedings of the DAGA (Vol. 44).
Updated on Thursday 27th of June, 2019
This page uses HTML5, CSS, and JavaScript