Several methods and interfaces for making the implementation of synthesized speech in desired applications easier have been developed during this decade. It is quite clear that it is impossible to create a standard for speech synthesis methods because most systems act as stand alone device which means they are incompatible with each other and do not share common parts. However, it is possible to standardize the interface of data flow between the application and the synthesizer.
Usually, the interface contains a set of control characters or variables for controlling the synthesizer output and features. The output is usually controlled by normal play, stop, pause, and resume type commands and the controllable features are usually pitch baseline and range, speech rate, volume, and in some cases even different voices, ages, and genders are available. In most frameworks it is also possible to control other external applications, such as a talking head or video.
In this chapter, three approaches to standardize the communication between a speech synthesizer and applications are introduced. Most of the present synthesis systems support so called Speech Application Programming Interface (SAPI) which makes easier the implementation of speech in any kind of application. For Internet purposes several kind of speech synthesis markup languages have been developed to make it possible to listen to synthesized speech without having to transfer the actual speech signal through network. Finally, one of the most interesting approaches is probably the TTS subpart of MPEG-4 multimedia standard which will be introduced in the near future.
7.1 Speech Application Programming Interface
SAPI is an interface between applications and speech technology engines, both text-to-speech and speech recognition (Amundsen 1996). The interface allows multiple applications to share the available speech resources on a computer without having to program the speech engine itself. Speech synthesis and recognition applications usually require plenty of computational resources and with SAPI approach lots of these resources may be saved. The user of an application can also choose the synthesizer used as long as it supports SAPI. Currently SAPIs are available for several environments, such as MS-SAPI for Microsoft Windows operating systems and Sun Microsystems Java SAPI (JSAPI) for JAVA based applications. In this chapter, only the speech synthesis part is discussed.
SAPI text-to-speech part consists of three interfaces. The voice text interface which provides methods to start, pause, resume, fast forward, rewind, and stop the TTS engine during speech. The attribute interface allows access to control the basic behavior of the TTS engine, such as the audio device to be used, the playback speed (in words per minute), and turning the speech on and off. With some TTS systems the attribute interface may also be used to select the speaking mode from predefined list of voices, such as female, male, child, or alien. Finally, the dialog interface can be used to set and retrieve information regarding the TTS engine to for example identify the TTS engine and alter the pronunciation lexicon.
The SAPI model defines 15 different control tags that can be used to control voice characteristics, phrase modification, and low-level synthesis. The voice character tags can be used to set high-level general characteristics of the voice, such as gender, age, or feelings of the speaker. The tag may also be used to tell the TTS engine the context of the message, such as plain text, e-mail, or address and phone numbers. The phrase modification tags may be used to adjust the pronunciation at word-by-word or phrase-by-phrase level. User can control for example the word emphasis, pauses, pitch, speed, and volume. The low-level tags deal with attributes of the TTS engine itself. User can for example add comments to the text, control the pronunciation of a word, turn prosody rules on and off, or reset the TTS engine to default settings. Only the reset tag of the low-level tags is commonly used (Amundsen 1996).
The control tags are separated with the backslash symbol from text to be spoken (\Tag="Parameter" or "value"\). The control tags are not case sensitive, but white-space sensitive. For example, \spd=200\ is the same as \SPD=200\, but \Spd=200\ is not the same as \ Spd=200 \. If the TTS engine encounters an unknown control tag, it just ignores it. The following control tags and their examples are based on MS-SAPI (Amundsen 1996).
The voice character control tags:
Chr
Used to set the character of the voice. More than one charasteristic can be applied at the same time. The default value is normal and the other values may be for example angry, excited, happy, scared, quiet, loud, and shout.
\Chr="Angry","Loud"\ Give me that! \Chr="Normal"\ Thanks.
\Chr="Excited"\ I am very excited. \Chr="Normal"\
Ctx
Used to set the context of spoken text. The context parameter may be for example address, C, document, E-mail, numbers/dates, or spreadsheet. The default value is unknown. In the following example the TTS engine converts the "W. 7th St." to "West seventh street", but fails to do so when the \ctx="unknown"\ tag is used. The e-mail address is converted as "sami dot lemmetty at hut dot fi".
\Ctx="Address"\ 1204 W. 7th St., Oak Ridge, TN.
\Ctx="E-mail"\ sami.lemmetty@hut.fi.
\Ctx="unknown"\ 129 W. 1st Avenue.
Vce
Used to set additional characteristics of the voice. Several character types can be set in a single call. Character types may be for example language, accent, dialect, gender, speaker, age, and style.
\Vce=Language="English", Accent="French"\ This is English with a French accent. \Vce=Gender="Male"\ I can change my gender easily from male to \Vce=Gender="Female"\ female.
The phrase modification control tags:
Emp
Used to add emphasis to a single word followed by the tag. In the following sentences the words "told" and "important" are emphasized.
I \Emp\ told you never go running in the street.
You must listen to me when I tell you something \Emp\ important.
Pau
Used to place a silent pause into the output stream. The duration of pause is given in milliseconds.
Pause of one \Pau=1000\ second.
Pit
Used to alter the base pitch of the output. The pitch is measured in Hertz between 50 Hz and 400 Hz. The pitch setting does not automatically revert the default value after a message has been spoken so it must be done manually.
\Pit=200\ You must listen to me \Pit=100\.
Spd
Used to set the base speed of the output. The speed is measured in words per minute between 50 and 250.
\Spd=50\ This is slow, but \Spd=200\ this is very fast.
Vol
Used to set the base volume of the output. The value can range from 0 (quiet) to 65535 (loud).
\Vol=15000\ Hello. \Vol=60000\ Hello!! \Vol=30000\
The low-level TTS control tags:
Com
Used to add comments to the text passed to the TTS engine. These comments will be ignored by the TTS engine.
\Com="This is a comment"\
Eng
Used to call an engine-specific command.
Mrk
Used to mark specific bookmarks. Can be used for signalling such things as page turns or slide changes once the place in the text is reached.
Prn
Used to embed custom pronunciations of words using the International Phonetic Alphabet (IPA).
Pro
Used to turn on and off the TTS prosody rules. Value 1 turns the settings off and value 0 turns them on.
Prt
Used to tell the TTS engine what part of speech the current word is. The categories may be for example abbreviation, noun, adjective, ordinal number, preposition, or verb. The following example defines word "is" as a verb, and word "beautiful" as an adjective.
This flower \Prt="V"\ is \Prt="Adj"\ beautiful.
Rst
Used to reset the control values to those that existed at the start of the current session.
7.2 Internet Speech Markup Languages
Most synthesizers accept only plain text as input. However, it is difficult to analyze the text and find correct pronunciation and prosody from written text. In some cases there is also need to include the speaker features or emotional information in the output speech. With some additional information in input data it is possible to control these features of speech easily. For example, with some information about if the input sentence is in a question, imperative, or neutral form, the controlling of prosody may become significantly easier. Some commercial systems allow the user to place same kind of annotations in the text to produce more natural sounding speech. These are for example DECtalk and the Bell Labs system described more closely in Chapter 9.
In normal HTML (Hyper-Text Markup Language), certain markup tags like <p> ... </p> are used to delimit paragraphs and help the web-browser to construct the correct output. These and same kind of additional tags may be used to help a speech synthesizer produce correct output with different kind of pronunciations, voices and other features. For example, to describe happiness, we may use tags <happy>...</happy> or to describe a question <quest>...</quest>. Speaker's features and used language may be controlled by same way with tags <gender=female> or <lang=fin>. Some words and common names have anomalous pronunciation which may be corrected with same kind of tags. Local stress markers may also be used to stress a certain word in a sentence.
The first attempt to develop a TTS markup language was called SSML (Speech Synthesis Markup Language), developed at the Centre for Speech Technology Research (CSTR) in the University of Edinburgh, England, in 1995 (Taylor et al. 1997). It included control tags for phase boundaries, language, and made possible to define a pronunciation of a specific word and include emphasis tags in the sentence. In the following example, pro defines the pronunciation of the word and format defines the used lexicon standard. With tag <phrase> it is even possible to change the meaning of the whole sentence.
<ssml>
<define word= "edinburgh" pro="EH1 D AH0 N B ER2 OW0" format= "cmudict.1.0>
<phrase> I saw the man in the park <phrase> with the telescope </phrase>
<phrase> I saw the man <phrase> in the park with the telescope </phrase>
<phrase> The train is now standing on platform <emph> A </emph>
<language="italian">
<phrase> continua in italiano </phrase>
</ssml>
Currently the development of the language is continuing with Bell Laboratories (Sproat et al. 1997). The latest version is called STML (Spoken Text Markup Language). SUN Microsystems is also participating in the development process to merge their JSML (Java Speech Markup Language) to achieve one widespread system in the near future. Currently, the controllable features are much wider than in SSML.
The structure of STML is easiest to apprehend from the example below. The used language and the default speaker of that language are set simply with tags <language id> and <speaker id>. The tag <genre type> allows to set the type of text like plain prose, poetry, or lists. The tag <div type> specifies a particular text-genre-specific division with list items. With tag <emph> the emphasis level of the following word is specified. The tag <phonetic> specifies that the enclosed region is a phonetic transcription in one of a predefined set of schemes. The tag <define> is used to specify the lexical pronunciation of a certain word. The tag <intonat> specifies the midline and amplitude of pitch range with absolute scale in hertz or relative multiplier compared to normal pitch for the speaker. The tag <bound> is used to define an intonational boundary between 0 (weakest) and 5 (strongest). The <literal mode> is used for spelling mode and the <omitted> tag specifies the region that is emitted from output speech.
In the following example some of the essential features of STML are presented.
<!doctype stml system>
<stml>
<language id=english>
<speaker id=male1>
<genre type=plain>
In this example, we see some <emph> particular </emph> STML tags, including:
<genre type=list>
language specification <div type=item>
speaker specification <div type=item>
text type (genre) specifications <div type=item>
<phonetic scheme=native> f&n"etik </phonetic> specifications
phrase boundary <bound type=minor> specifications
</genre>
<define word="edinburgh" pro="e 1 d i n b 2 r
@ @ " scheme="cstr">The Edinburgh and Bell labs systems now pronounce word Edinburgh correctly.
Some text in <literal mode=spell> literal mode </literal>
<omitted verbose=yes> you hear nothing </omitted>
<rate speed=250 scheme=wpm> this is faster </rate>
...
</genre>
</speaker>
</language>
</stml>
Markup languages provide some advantages compared to for example SAPI which provides tags only for speaker directives, not for any text description. In theory, anything specifiable in the text which can give an instruction or description to a TTS system could be in a synthesis markup language. Unfortunately, several systems are under development and the making of an international standard is a considerable problem.
The MPEG-4 Text-to-Speech (M-TTS) is a subpart of the standard which is currently under development in ISO MPEG-4 committee (ISO 1997). It specifies the interface between the bitstream and listener. Naturally, due to various existing speech synthesis techniques the exact synthesis method is not under standardization. The main objective is to make it possible to include narration in any multimedia content without having to record natural speech. Also controlling of facial animation (FA) and moving picture (MP) is supported. Because MPEG-4 TTS system is still under development, it is only discussed briefly below. Further and more up-to-date information is available in MPEG-homepage (MPEG 1998).
The M-TTS bitstream consists of two parts, the sequence part and the sentence part. Both parts begin with start code and ID code. The sequence part contains the information of what features are included in the bit stream. It consists of enable flags for gender, age, speech rate, prosody, video, lip-shape, and trick mode. Used language is also specified in this part with 18 bits. The sentence part contains all the information which is enabled in the sequence part and the text to be synthesized with phonetic symbols used. Also the length of silence sections are defined in this section. Used variables are described in Table 7.1., where for example the notation '8 x L' in TTS_Text means that the TTS_Text is indexed with the Length_of_Text.
Table 7.1. The M-TTS sentence part description.
|
String |
Description |
Bits |
|
Silence |
Set to 1 when the current position is silence. |
1 |
|
Silence_Duration |
Silence segment in milliseconds (0 prohibited). |
12 |
|
Gender |
Speakers gender. 1 if male and 0 if female. |
1 |
|
Age |
Speaker age, 8 levels, below 6 to over 60. |
3 |
|
Speech_Rate |
Synthetic speech rate in 16 levels. |
4 |
|
Length_of_Text |
Length of TTS_Text data in bytes (L). |
12 |
|
TTS_Text |
Character string containing the input string. |
8 x L |
|
Dur_Enable |
Set to 1 when duration data exists. |
1 |
|
F0_Contour_Enable |
Set to 1 when pitch contour information exists. |
1 |
|
Energy_Contour_Enable |
Set to 1 when energy contour information exists. |
1 |
|
Number_of_Phonemes |
Number of phonemes needed for synthesis of input text. (NP) |
10 |
|
Phonemes_Symbols_Lenght |
The length of Phoneme_Symbols data in bytes. (P) |
13 |
|
Phoneme_Symbols |
The indexing number for the current phoneme. |
8 x P |
|
Dur_each_Phoneme |
The duration of each phoneme in milliseconds. |
12 x NP |
|
F0_Contour_each_Phoneme |
The pitch for the current phoneme in Hz. |
8 x NP x 3 |
|
Energy_Contour_each_Phoneme |
The energy level of current phoneme in integer dB for three points (0, 50, 100% positions of the phoneme). |
8 x NP x 3 |
|
Sentence_Duration |
The duration of sentence in milliseconds. |
16 |
|
Position_in_Sentence |
The position of the current stop in a sentence. (Elapsed time in milliseconds) |
16 |
|
Offset |
The duration of short pause before the start of speech in msec. |
10 |
|
Number_of_Lip_Shape |
The number of lip-shape patterns to be processed. (N) |
10 |
|
Lip_Shape_in_Sentence |
The position of each lip shape from the beginning of the sentence in milliseconds. (L) |
16 x N |
|
Lip_Shape |
The indexing number for the current lip shape for MP. |
8 x L |
The parameters are described more closely in ISO (1996). For example, prosody_enable bit in sequence part enables duration, f0contour, and energy contour in sentence part making prosodic features available.
7.3.2 Structure of MPEG-4 TTS Decoder
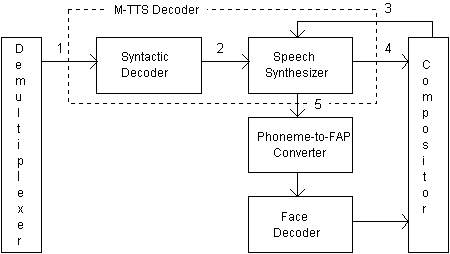
The structure of an M-TTS decoder is presented in Figure 7.1. Only the interfaces are the subjects of standardization process. There are five interfaces:
When decoder receives the M-TTS bitstream it is first demultiplexed (1) and sent to the syntactic decoder which specifies the bitstream sent to speech synthesizer (2) including some of the following: The input type of the M-TTS data, control commands stream, input text to be synthesized, and some additional information, such as prosodic parameters, lip-shape patterns, and information for the trick mode operation.
Fig. 7.1. MPEG-4 Audio TTS decoder architecture.
The interface from compositor to speech synthesizer (3) is defined to allow the local control of synthesized speech by user. The user interface can support several features, such as trick mode (play, stop, forward, backward etc.) and prosody (speech rate, pitch, gender, age etc.). Trick mode is synchronized with moving picture.
The interface from speech synthesizer to compositor (4) defines the data structure of encoded digital speech. It is identical to the interface for digitized natural speech to the compositor. Finally, the interface between speech synthesizer and phoneme-to-FAP converter (5) defines the data structure between these modules. The phoneme-to-FAP converter is driven and synchronized with speech synthesizer by phoneme information. The data structure consists of phoneme symbol and duration with average fundamental frequency.
7.3.3 Applications of MPEG-4 TTS
M-TTS presents two application scenarios for the M-TTS Decoder, MPEG-4 Story Teller on Demand (STOD) and MPEG-4 Audio Text-to-Speech with Moving Picture. These scenarios are only informative and they are not under standardization process. Naturally, MPEG-4 TTS may be used in several other audio-visual related applications, such as dubbing-tools for animated pictures or Internet voice.
Story Teller on Demand is an application where user can select huge databases or story libraries stored on hard disk, CD-ROM or other media. The system reads the story via M-TTS decoder with the MPEG-4 facial animation or with appropriately selected images. The user can stop and resume speaking at any moment he wants with for example mouse or keyboard. The gender, age, and the speech rate of the story teller are also easily adjustable. With the STOD system, the narration with several features can be easily composed without recording the natural speech and so the required disk space is considerably reduced.
Audio Text-to-Speech with Moving picture is an application where the synchronized playback of the M-TTS decoder and encoded moving picture is the main objective. The decoder can provide several granularities of synchronization for different situations. Aligning only the composition time of each sentence, coarse granularity of synchronization and trick mode functionality can be easily achieved. For finer synchronization granularity the lip shape information may be utilized. The finest granularity can be achieved by using the prosody and video-related information. With this synchronization capability, the M-TTS decoder may be used for moving picture dubbing by utilizing the lip shape pattern information.
In the future M-TTS or other similar approaches may be used in several multimedia and telecommunication applications. However, it may take some time before we have full synthetic newsreaders and narrators. Some of the present synthesizers are using a same kind of controlling approach in their system, but there is still no efforts for widespread standard.