2. History and Development of Speech Synthesis
Artificial speech has been a dream of the humankind for centuries. To understand how the present systems work and how they have developed to their present form, a historical review may be useful. In this chapter, the history of synthesized speech from the first mechanical efforts to systems that form the basis for today's high-quality synthesizers is discussed. Some separate milestones in synthesis-related methods and techniques will also be discussed briefly. For more detailed description of speech synthesis development and history see for example Klatt (1987), Schroeder (1993), and Flanagan (1972, 1973) and references in these.
2.1 From Mechanical to Electrical Synthesis
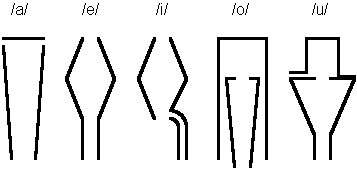
The earliest efforts to produce synthetic speech were made over two hundred years ago (Flanagan 1972, Flanagan et al. 1973, Schroeder 1993). In St. Petersburg 1779 Russian Professor Christian Kratzenstein explained physiological differences between five long vowels (/a/, /e/, /i/, /o/, and /u/) and made apparatus to produce them artificially. He constructed acoustic resonators similar to the human vocal tract and activated the resonators with vibrating reeds like in music instruments. The basic structure of resonators is shown in Figure 2.1. The sound /i/ is produced by blowing into the lower pipe without a reed causing the flute-like sound.
Fig. 2.1. Kratzenstein's resonators (Schroeder 1993).
A few years later, in Vienna 1791, Wolfgang von Kempelen introduced his "Acoustic-Mechanical Speech Machine", which was able to produce single sounds and some sound combinations (Klatt 1987, Schroeder 1993). In fact, Kempelen started his work before Kratzenstein, in 1769, and after over 20 years of research he also published a book in which he described his studies on human speech production and the experiments with his speaking machine. The essential parts of the machine were a pressure chamber for the lungs, a vibrating reed to act as vocal cords, and a leather tube for the vocal tract action. By manipulating the shape of the leather tube he could produce different vowel sounds. Consonants were simulated by four separate constricted passages and controlled by the fingers. For plosive sounds he also employed a model of a vocal tract that included a hinged tongue and movable lips. His studies led to the theory that the vocal tract, a cavity between the vocal cords and the lips, is the main site of acoustic articulation. Before von Kempelen's demonstrations the larynx was generally considered as a center of speech production. Kempelen received also some negative publicity. While working with his speaking machine he demonstrated a speaking chess-playing machine. Unfortunately, the main mechanism of the machine was concealed, legless chess-player expert. Therefore his real speaking machine was not taken so seriously as it should have (Flanagan et al. 1973, Schroeder 1993).
In about mid 1800's Charles Wheatstone constructed his famous version of von Kempelen's speaking machine which is shown in Figure 2.2. It was a bit more complicated and was capable to produce vowels and most of the consonant sounds. Some sound combinations and even full words were also possible to produce. Vowels were produced with vibrating reed and all passages were closed. Resonances were effected by deforming the leather resonator like in von Kempelen's machine. Consonants, including nasals, were produced with turbulent flow trough a suitable passage with reed-off .
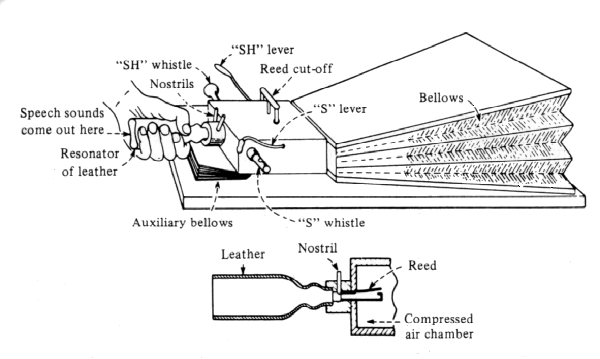
Fig. 2.2. Wheatstone's reconstruction of von Kempelen's speaking machine (Flanagan 1972).
The connection between a specific vowel sound and the geometry of the vocal tract was found by Willis in 1838 (Schroeder 1993). He synthesized different vowels with tube resonators like organ pipes. He also discovered that the vowel quality depended only on the length of the tube and not on its diameter.
In late 1800's Alexander Graham Bell with his father, inspired by Wheatstone's speaking machine, constructed same kind of speaking machine. Bell made also some questionable experiments with his terrier. He put his dog between his legs and made it growl, then he modified vocal tract by hands to produce speech-like sounds (Flanagan 1972, Shroeder 1993).
The research and experiments with mechanical and semi-electrical analogs of vocal system were made until 1960's, but with no remarkable success. The mechanical and semi-electrical experiments made by famous scientists, such as Herman von Helmholz and Charles Wheatstone are well described in Flanagan (1972), Flanagan et al. (1973), and Shroeder (1993).
2.2 Development of Electrical Synthesizers
The first full electrical synthesis device was introduced by Stewart in 1922 (Klatt 1987). The synthesizer had a buzzer as excitation and two resonant circuits to model the acoustic resonances of the vocal tract. The machine was able to generate single static vowel sounds with two lowest formants, but not any consonants or connected utterances. Same kind of synthesizer was made by Wagner (Flanagan 1972). The device consisted of four electrical resonators connected in parallel and it was excited by a buzz-like source. The outputs of the four resonators were combined in the proper amplitudes to produce vowel spectra. In 1932 Japanese researchers Obata and Teshima discovered the third formant in vowels (Schroeder 1993). The three first formants are generally considered to be enough for intelligible synthetic speech.
First device to be considered as a speech synthesizer was VODER (Voice Operating Demonstrator) introduced by Homer Dudley in New York World's Fair 1939 (Flanagan 1972, 1973, Klatt 1987). VODER was inspired by VOCODER (Voice Coder) developed at Bell Laboratories in the mid-thirties. The original VOCODER was a device for analyzing speech into slowly varying acoustic parameters that could then drive a synthesizer to reconstruct the approximation of the original speech signal. The VODER consisted of wrist bar for selecting a voicing or noise source and a foot pedal to control the fundamental frequency. The source signal was routed through ten bandpass filters whose output levels were controlled by fingers. It took considerable skill to play a sentence on the device. The speech quality and intelligibility were far from good but the potential for producing artificial speech were well demonstrated. The speech quality of VODER is demonstrated in accompanying CD (track 01).
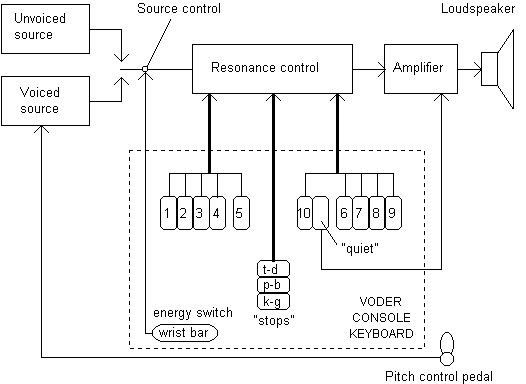
Fig. 2.3. The VODER speech synthesizer (Klatt 1987).
After demonstration of VODER the scientific world became more and more interested in speech synthesis. It was finally shown that intelligible speech can be produced artificially. Actually, the basic structure and idea of VODER is very similar to present systems which are based on source-filter-model of speech.
About a decade later, in 1951, Franklin Cooper and his associates developed a Pattern Playback synthesizer at the Haskins Laboratories (Klatt 1987, Flanagan et al. 1973). It reconverted recorded spectrogram patterns into sounds, either in original or modified form. The spectrogram patterns were recorded optically on the transparent belt (track 02).
The first formant synthesizer, PAT (Parametric Artificial Talker), was introduced by Walter Lawrence in 1953 (Klatt 1987). PAT consisted of three electronic formant resonators connected in parallel. The input signal was either a buzz or noise. A moving glass slide was used to convert painted patterns into six time functions to control the three formant frequencies, voicing amplitude, fundamental frequency, and noise amplitude (track 03). At about the same time Gunnar Fant introduced the first cascade formant synthesizer OVE I (Orator Verbis Electris) which consisted of formant resonators connected in cascade (track 04). Ten years later, in 1962, Fant and Martony introduced an improved OVE II synthesizer, which consisted of separate parts to model the transfer function of the vocal tract for vowels, nasals, and obstruent consonants. Possible excitations were voicing, aspiration noise, and frication noise. The OVE projects were followed by OVE III and GLOVE at the Kungliga Tekniska Högskolan (KTH), Sweden, and the present commercial Infovox system is originally descended from these (Carlson et al. 1981, Barber et al. 1989, Karlsson et al. 1993).
PAT and OVE synthesizers engaged a conversation how the transfer function of the acoustic tube should be modeled, in parallel or in cascade. John Holmes introduced his parallel formant synthesizer in 1972 after studying these synthesizers for few years. He tuned by hand the synthesized sentence "I enjoy the simple life" (track 07) so good that the average listener could not tell the difference between the synthesized and the natural one (Klatt 1987). About a year later he introduced parallel formant synthesizer developed with JSRU (Joint Speech Research Unit) (Holmes et al. 1990).
First articulatory synthesizer was introduced in 1958 by George Rosen at the Massachusetts Institute of Technology, M.I.T. (Klatt 1987). The DAVO (Dynamic Analog of the VOcal tract) was controlled by tape recording of control signals created by hand (track 11). In mid 1960s, first experiments with Linear Predictive Coding (LPC) were made (Schroeder 1993). Linear prediction was first used in low-cost systems, such as TI Speak'n'Spell in 1980, and its quality was quite poor compared to present systems (track 13). However, with some modifications to basic model, which are described later in Chapter 5, the method has been found very useful and it is used in many present systems.
The first full text-to-speech system for English was developed in the Electrotehnical Laboratory, Japan 1968 by Noriko Umeda and his companions (Klatt 1987). It was based on an articulatory model and included a syntactic analysis module with sophisticated heuristics. The speech was quite intelligible but monotonous and far away from the quality of present systems (track 24).
In 1979 Allen, Hunnicutt, and Klatt demonstrated the MITalk laboratory text-to-speech system developed at M.I.T. (track 30). The system was used later also in Telesensory Systems Inc. (TSI) commercial TTS system with some modifications (Klatt 1987, Allen et al. 1987). Two years later Dennis Klatt introduced his famous Klattalk system (track 33), which used a new sophisticated voicing source described more detailed in (Klatt 1987). The technology used in MITalk and Klattalk systems form the basis for many synthesis systems today, such as DECtalk (tracks 35-36) and Prose-2000 (track 32). For more detailed information of MITalk and Klattalk systems, see for example Allen et al. (1987), Klatt (1982), or Bernstein et al. (1980).
The first reading aid with optical scanner was introduced by Kurzweil in 1976. The Kurzweil Reading Machines for the Blind were capable to read quite well the multifont written text (track 27). However, the system was far too expensive for average customers (the price was still over $ 30 000 about ten years ago), but were used in libraries and service centers for visually impaired people (Klatt 1987).
In late 1970's and early 1980's, considerably amount of commercial text-to-speech and speech synthesis products were introduced (Klatt 1987). The first integrated circuit for speech synthesis was probably the Votrax chip which consisted of cascade formant synthesizer and simple low-pass smoothing circuits. In 1978 Richard Gagnon introduced an inexpensive Votrax-based Type-n-Talk system (track 28). Two years later, in 1980, Texas Instruments introduced linear prediction coding (LPC) based Speak-n-Spell synthesizer based on low-cost linear prediction synthesis chip (TMS-5100). It was used for an electronic reading aid for children and received quite considerable attention. In 1982 Street Electronics introduced Echo low-cost diphone synthesizer (track 29) which was based on a newer version of the same chip as in Speak-n-Spell (TMS-5220). At the same time Speech Plus Inc. introduced the Prose-2000 text-to-speech system (track 32). A year later, first commercial versions of famous DECtalk (tracks 35-36) and Infovox SA-101 (track 31) synthesizer were introduced (Klatt 1987). Some milestones of speech synthesis development are shown in Figure 2.4.
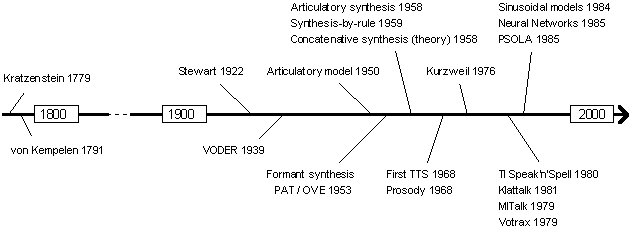
Fig. 2.4. Some milestones in speech synthesis.
Modern speech synthesis technologies involve quite complicated and sophisticated methods and algorithms. One of the methods applied recently in speech synthesis is hidden Markov models (HMM). HMMs have been applied to speech recognition from late 1970's. For speech synthesis systems it has been used for about two decades. A hidden Markov model is a collection of states connected by transitions with two sets of probabilities in each: a transition probability which provides the probability for taking this transition, and an output probability density function (pdf) which defines the conditional probability of emitting each output symbol from a finite alphabet, given that that the transition is taken (Lee 1989).
Neural networks have been applied in speech synthesis for about ten years and the latest results have been quite promising. However, the potential of using neural networks have not been sufficiently explored. Like hidden Markov models, neural networks are also used successfully with speech recognition (Schroeder 1993).
2.3 History of Finnish Speech Synthesis
Although Finnish text corresponds well to its pronunciation and the text preprocessing scheme is quite simple, researchers had paid quite little attention to Finnish TTS before early 1970's. On the other hand, compared to English, the potential number of users and markets are quite small and developing process is time consuming and expensive. However, this potential is increasing with the new multimedia and telecommunication applications.
The first proper speech synthesizer for Finnish, SYNTE2, was introduced in 1977 after five years research in Tampere University of Technology (Karjalainen et al. 1980, Laine 1989). SYNTE2 was also among the first microprocessor based synthesis systems and the first portable TTS system in the world. About five years later an improved SYNTE3 synthesizer was introduced and it was a market leader in Finland for many years. In 1980's, several other commercial systems for Finnish were introduced. For example, Amertronics, Brother Caiku, Eke, Humanica, Seppo, and Task, which all were based on the Votrax speech synthesis chip (Salmensaari 1989).
From present systems, two concatenation-based synthesizers, Mikropuhe and Sanosse, are probably the best known products for Finnish. Mikropuhe has been developed by Timehouse Corporation during last ten years. The first version produced 8-bit sound only from the PC's internal speaker. The latest version is much more sophisticated and described more closely in Chapter 9. Sanosse synthesizer has been developed during last few years for educational purposes for University of Turku and the system is also adopted by Sonera (former Telecom Finland) for their telecommunication applications. Also some multilingual systems including Finnish have been developed during last decades. The best known such system is probably the Infovox synthesizer developed in Sweden. These three systems are perhaps the most dominant products in Finland today (Hakulinen 1998).